
Web制作でHTMLを修正した際、不要なCSSが残ったり、逆にクラスを書き忘れたりすることはありませんか?この記事では、Rubyを使ってHTMLファイルとCSSファイルを照合し、クラスの不整合を自動で抽出するスクリプトを紹介します。(スクリプト:一般的にはプログラムには準備(コンパイル)が必要だけど、スクリプトは作ってすぐに動かせるプログラムなので手軽)
| チェック項目 | 手動(目視) | このスクリプト |
| 正確性 | 見落としが発生しやすい | 機械的に100%抽出 |
| 作業時間 | 数十分〜 | 数秒 |
| 対応範囲 | 1ファイルが限界 | 複数クラスも一括判定 |
前提条件(実行環境)
このスクリプトを動かすには、以下の環境とライブラリが必要です。
- 開発言語 : Ruby 3.x 以上
- 対象ファイル :
.htmlファイルおよび.cssファイル(同じディレクトリ内、またはサブディレクトリ内) - 必要なライブラリ(Gem):
nokogiri: HTMLの構造を解析し、クラス名を取り出すために使用します。css_parser: CSSファイルを解析し、定義されているスタイルを読み取るために使用します。
↓以下は、具体的な手順です。
PCにRubyを入れてみる
まず自分のPCにRubyが入っているか、確認
コマンドプロンプトを立ち上げて
ruby -vと入れてみる。
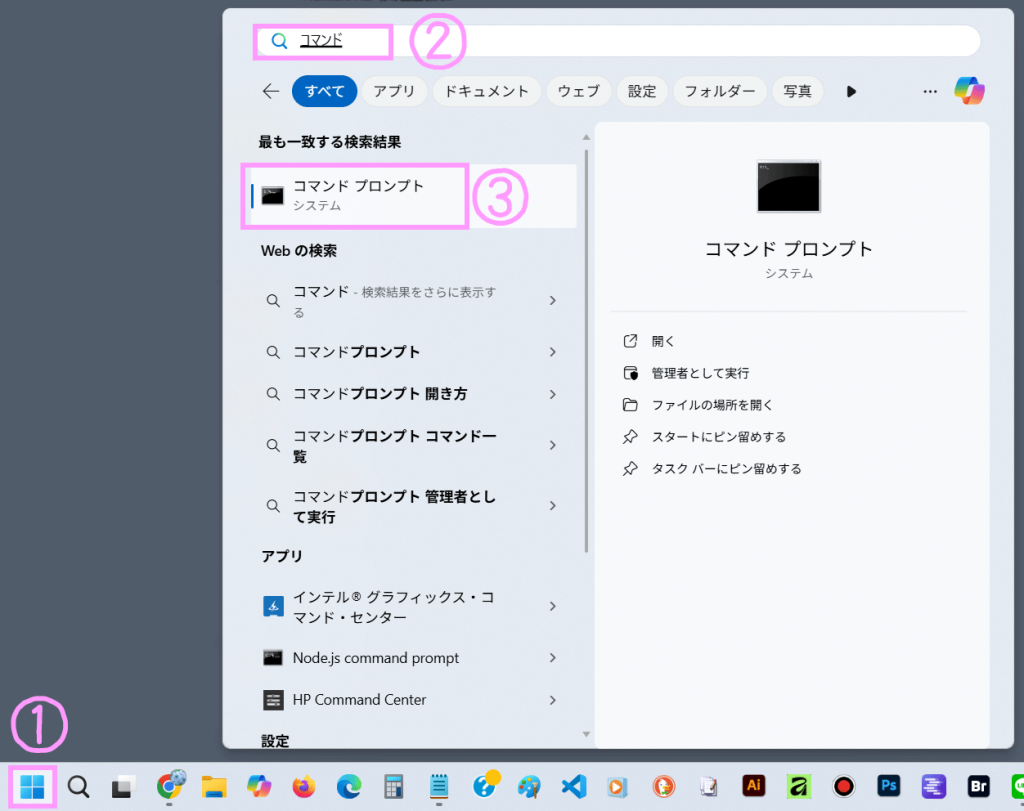
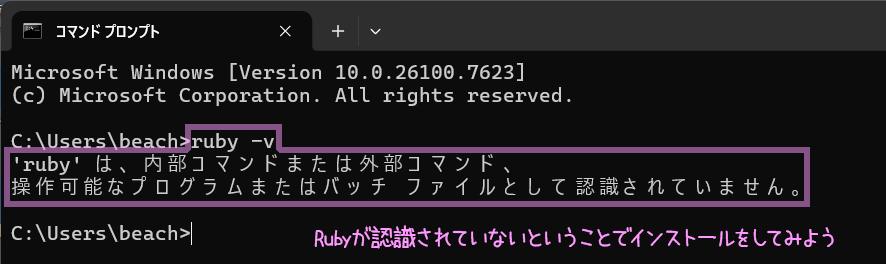
「Rubyは…認識されていません」ってことで、入ってない。
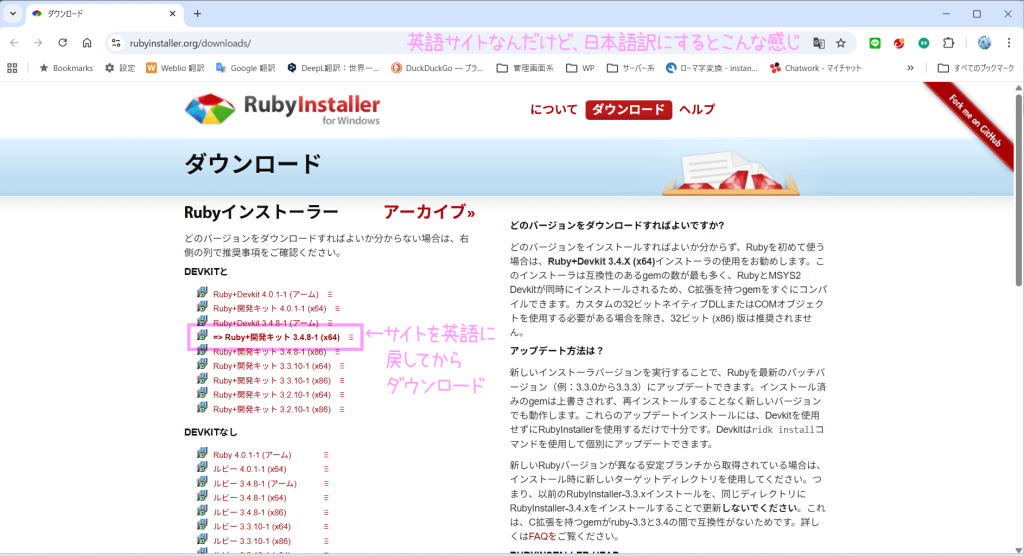
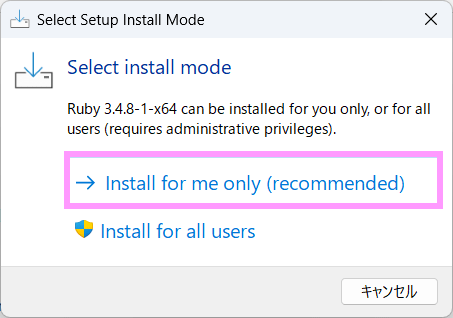
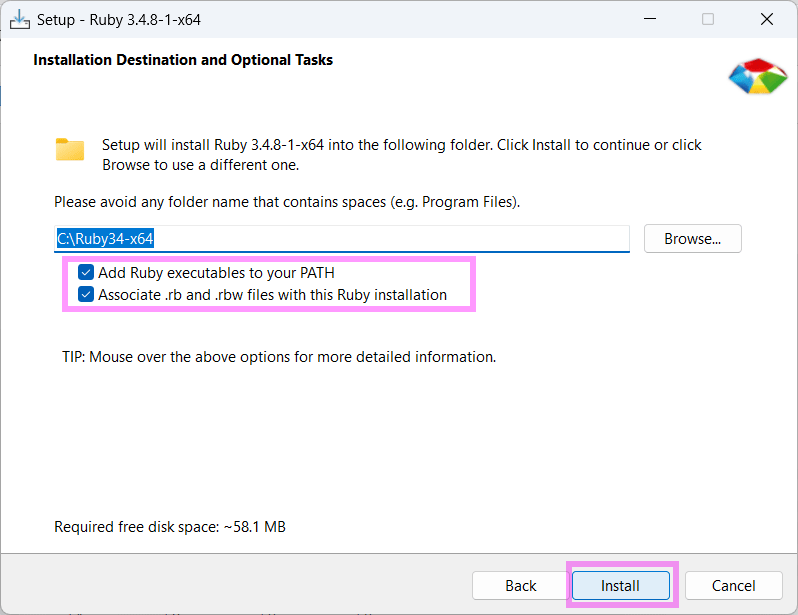
Rubyのサイトに行って、ダウンロード → インストール

太字になっているのがオススメだと思うんだ。
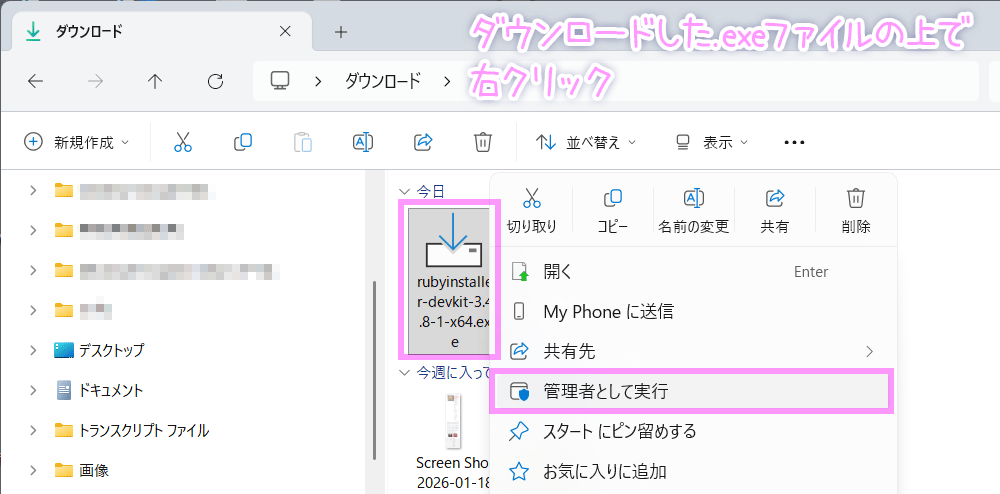

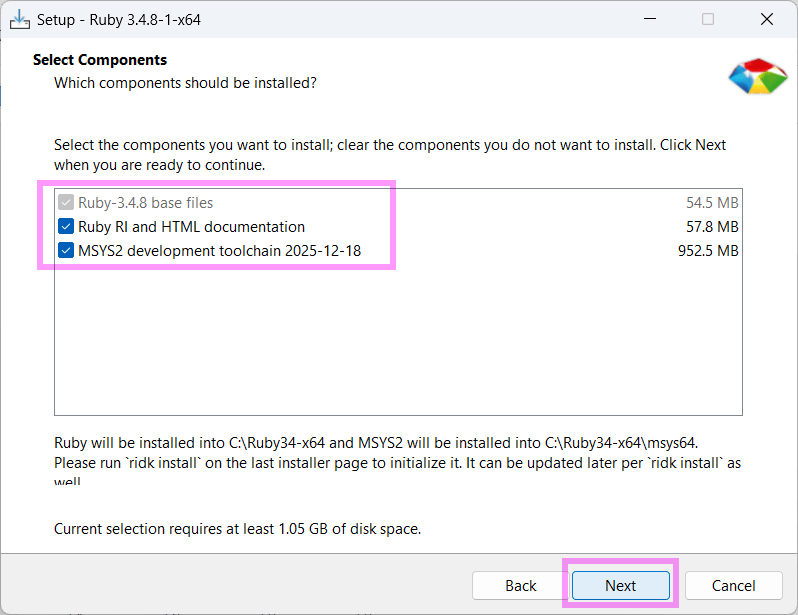
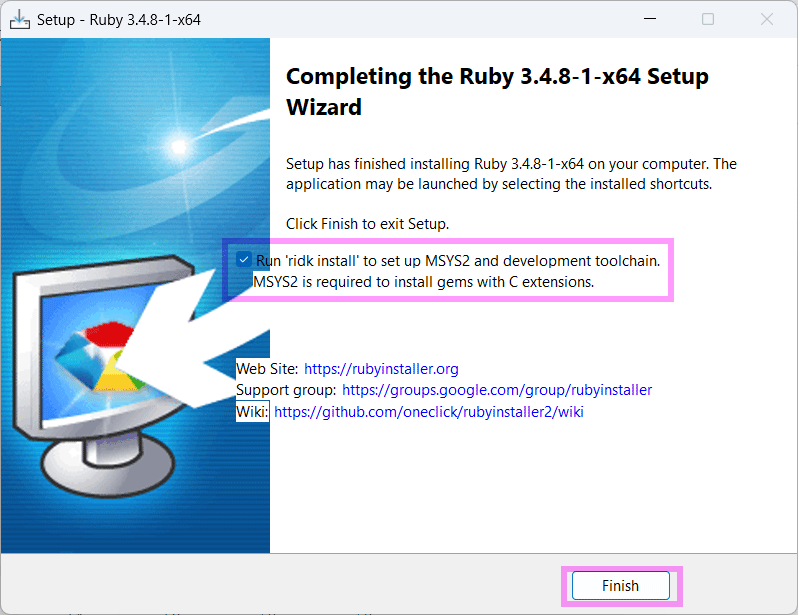
Rubyがインストールできたら
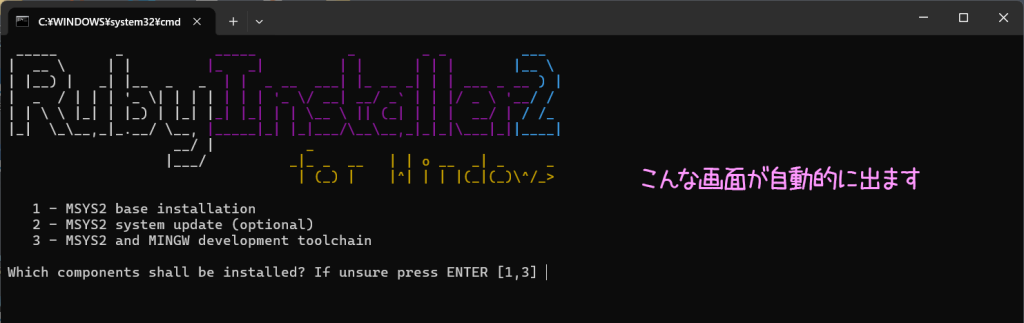
この画面の一番下にある Which components shall be installed? If unsure press ENTER [1,3] の横に、半角数字の 3 を入力して、キーボード「Enter」キー。
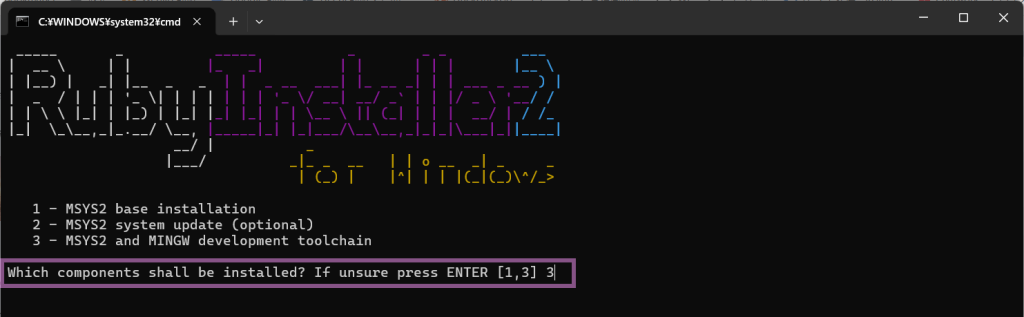
たーくさん、文字が出てきます。succeeded(成功)が出ればOKとのこと。
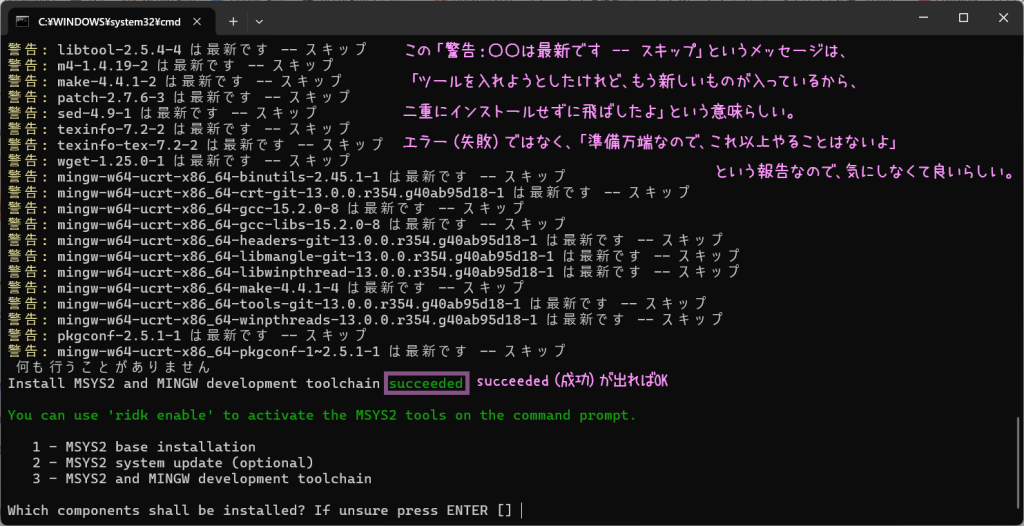
succeeded(成功)が確認できたら、この画面は閉じる。
Gemのインストール
またまたコマンドプロンプトを立ち上げる。

gem install nokogiri と入れ、エンターキー

▼「gem install nokogiri 」というコードの意味
gem : Rubyのライブラリ(gem)を管理するためのコマンド(インストール、アンインストールなど)。
install : 指定したライブラリ(gem)をインストールする命令。
nokogiri : インストールしたいライブラリの名前(HTML/XMLパーサー)。
gem install nokogiri は、「RubyでWebスクレイピング(Webサイトから情報を抽出・取得する)ための定番ライブラリであるNokogiriを、Rubyのパッケージ管理システム(gem)を使ってインストールする」という意味らしい。
1 gem installedと表示されれば成功
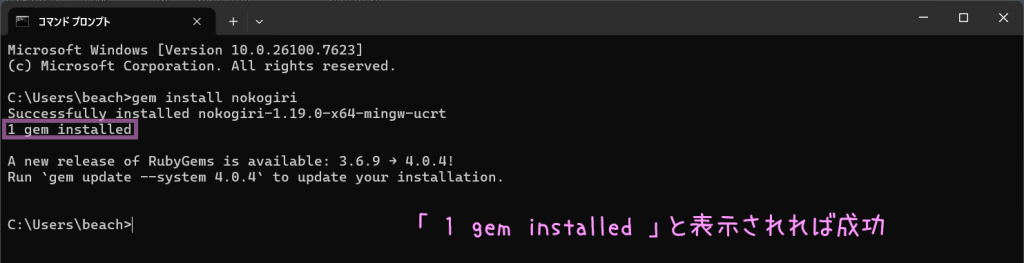
とりあえずこの画面はこれで閉じました(続けてできる気もするけど、ビビリなので)
CSSのチェック用のライブラリをインストール
紆余曲折の末、CSSもチェックしたいので、CSSチェック用のライブラリ「 css_parser 」を入れることに。またまたコマンドプロンプトを立ち上げる。
gem install css_parserと入れエンターキー。
1 gem installedと表示されれば成功。

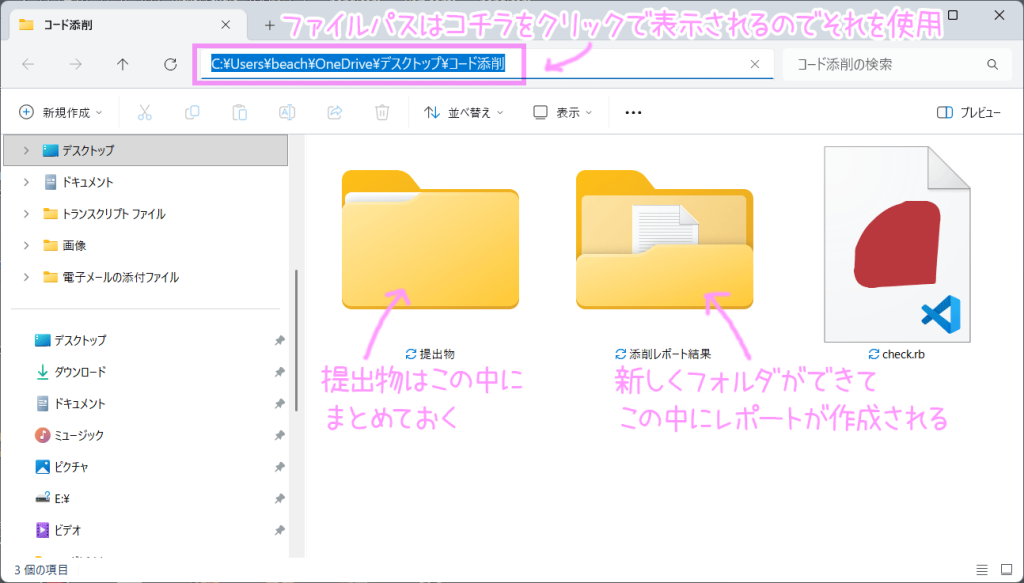
フォルダをデスクトップに作成
デスクトップに「 コード添削 」フォルダを作成。その中に「 提出物 」フォルダを作成。
Rubyのプログラムファイル(後述)も「 コード添削 」フォルダに入れる。
※「 提出物 」フォルダの中に、生徒さん達の提出フォルダ(サイトのデータ)を入れる。
RubyでHTMLとCSSのクラス差分をチェックするコードを作成
Rubyのコード(プログラムの命令文)は以下の通り。ファイル名は「 check.rb 」にする。
・・・まぁ、何人も見たら、改良しなければならないところがまた出てくるかもしれないけど、今の段階ではこんな感じ。
HTMLのバージョンはHTML5に固定。基本的な文法ができてるかチェック。リンクの不備、CSSは基本的な文法が合ってるかとクラスとIDの重複をチェック。使われていないクラスを検出。
require 'nokogiri'
require 'fileutils'
require 'pathname'
SUBMISSION_DIR = '提出物'
REPORT_DIR = '添削レポート結果'
FileUtils.mkdir_p(REPORT_DIR)
Dir.glob("#{SUBMISSION_DIR}/*").each do |student_path|
next unless File.directory?(student_path)
student_name = File.basename(student_path)
puts "添削中: #{student_name} ..."
report = ["========================================", " 生徒名: #{student_name} 様 添削レポート", "========================================\n"]
all_files = Dir.glob("#{student_path}/**/*", File::FNM_DOTMATCH).select { |f| File.file?(f) }
# --- 1. 事前準備:全HTMLから使用中のClass/IDをすべて収集 ---
all_htmls = Dir.glob("#{student_path}/**/*.html")
used_in_html_classes = []
used_in_html_ids = []
all_htmls.each do |html_path|
html_content = File.read(html_path, encoding: "UTF-8") rescue ""
doc = Nokogiri::HTML5.parse(html_content)
# Classの抽出
doc.css('[class]').each do |el|
used_in_html_classes += el['class'].split(/\s+/)
end
# IDの抽出
doc.css('[id]').each do |el|
used_in_html_ids << el['id'].delete('#')
end
end
used_in_html_classes.uniq!
used_in_html_ids.uniq!
# --- 2. 各HTMLファイルの解析(パス・文法・うっかりミス) ---
all_htmls.each do |html_path|
rel_html_path = Pathname.new(html_path).relative_path_from(Pathname.new(student_path)).to_s
report << "--- HTMLチェック: #{rel_html_path} ---"
current_dir = File.dirname(html_path)
current_folder_name = File.basename(current_dir)
html_lines = File.readlines(html_path, encoding: "UTF-8") rescue []
doc = Nokogiri::HTML5.parse(html_lines.join)
if doc.errors.any?
report << "❌ HTML文法にエラーがあります。"
else
report << "✅ HTML文法はエラー無です。"
# ID名に「#」を入れちゃうミス
doc.css('[id]').each do |el|
id_val = el['id']
if id_val && id_val.start_with?('#')
line_no = html_lines.find_index { |l| l.include?("id=\"#{id_val}\"") }
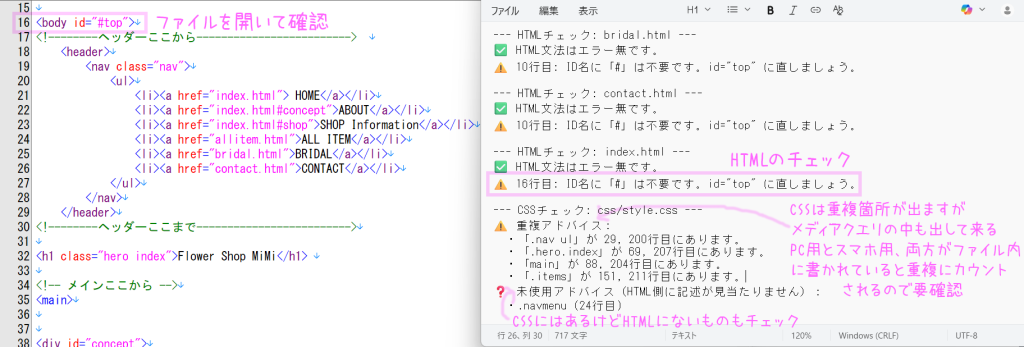
report << "⚠️ #{line_no ? line_no + 1 : '?'}行目: ID名に「#」は不要です。id=\"#{id_val.delete('#')}\" に直しましょう。"
end
end
# リンクチェック(スペース・冗長パス対応)
doc.css('img, a, link').each do |el|
attr_name = (el.name == 'img') ? 'src' : 'href'
path = el[attr_name]
next if path.nil? || path.strip.empty? || path.start_with?('http', 'mailto:', 'tel:')
line_no = html_lines.find_index { |l| l.include?(path) }
line_prefix = line_no ? "#{line_no + 1}行目: " : ""
# スペース異常の検知
if path.include?(" #") || path.end_with?(" ")
report << "⚠️ #{line_prefix}パスに不要なスペースがあります。「#{path.gsub(' ', '␣')}」を詰めましょう。"
end
# パスのクリーンアップと実在確認
clean_path = path.strip.gsub(" #", "#")
target_file_part = clean_path.split('#').first || ""
check_filename = target_file_part.empty? ? File.basename(html_path) : target_file_part
target_full_path = File.expand_path(check_filename, current_dir)
actual_file = all_files.find { |f| File.expand_path(f) == target_full_path }
if actual_file.nil?
report << "❌ #{line_prefix}リンク切れ「#{path}」"
else
actual_rel = Pathname.new(actual_file).relative_path_from(Pathname.new(current_dir)).to_s.gsub('\\', '/')
# 冗長パス
if clean_path.include?("../#{current_folder_name}/")
report << "⚠️ #{line_prefix}パスが冗長です。「#{actual_rel}」と短く書けます。"
elsif check_filename.gsub('\\', '/') != actual_rel && !path.include?(" #")
report << "⚠️ #{line_prefix}大文字・小文字不一致(指定:#{check_filename} ⇔ 実際:#{actual_rel})"
end
end
end
end
report << ""
end
# --- 3. CSS解析(重複チェック + 未使用セレクタ検出) ---
Dir.glob("#{student_path}/**/*.css").each do |path|
rel_css_path = Pathname.new(path).relative_path_from(Pathname.new(student_path)).to_s
report << "--- CSSチェック: #{rel_css_path} ---"
css_lines = File.readlines(path, encoding: "UTF-8") rescue []
raw_selectors = []
unused_items = []
css_lines.each_with_index do |line, idx|
if line.include?('{')
selector = line.split('{').first.strip.gsub(/\s+/, " ")
raw_selectors << { name: selector, line: idx + 1 }
# HTMLで使われていないクラス・IDを抽出
# クラス (.name)
selector.scan(/\.([a-zA-Z0-9\-_]+)/).flatten.each do |cls|
unused_items << ".#{cls} (#{idx + 1}行目)" unless used_in_html_classes.include?(cls)
end
# ID (#name)
selector.scan(/#([a-zA-Z0-9\-_]+)/).flatten.each do |id_name|
next if id_name == "top" # ページトップ用IDは除外
unused_items << "##{id_name} (#{idx + 1}行目)" unless used_in_html_ids.include?(id_name)
end
end
end
# 重複チェック
selector_names = raw_selectors.map { |s| s[:name] }
duplicates = selector_names.select { |s| selector_names.count(s) > 1 }.uniq
if !duplicates.empty?
report << "⚠️ 重複アドバイス:"
duplicates.each do |target|
lines = raw_selectors.select { |s| s[:name] == target }.map { |s| s[:line] }
report << " ・「#{target}」が #{lines.join(', ')}行目にあります。"
end
end
# 未使用アドバイス
if !unused_items.empty?
report << "❓ 未使用アドバイス(HTML側に記述が見当たりません):"
unused_items.uniq.each { |item| report << " ・#{item}" }
end
report << "✅ チェック完了" if duplicates.empty? && unused_items.empty?
report << ""
end
report << "========================================\n"
File.write("#{REPORT_DIR}/#{student_name}_レポート.txt", report.join("\n"), mode: "w:UTF-8")
end
puts "\n✨ 未使用CSS検出機能を含む【完全版】の添削が完了しました!"HTMLとCSSをチェックするスクリプトの実行手順と結果の見方
HTMLとCSSをチェックするスクリプトの実行手順
スクリプト(プログラム)を実行するときは、コマンドプロンプトから。
↓私の「 コード添削 」フォルダのファイルパスを入れて、そちらへ移動。
cd /d "C:\Users\username\デスクトップ\コード添削"※コードは例。パスの中に日本語が含まれる場合、全体を ” “(ダブルクォーテーション)で囲む。
↓先ほど作った「 check.rb 」を実行する
ruby check.rb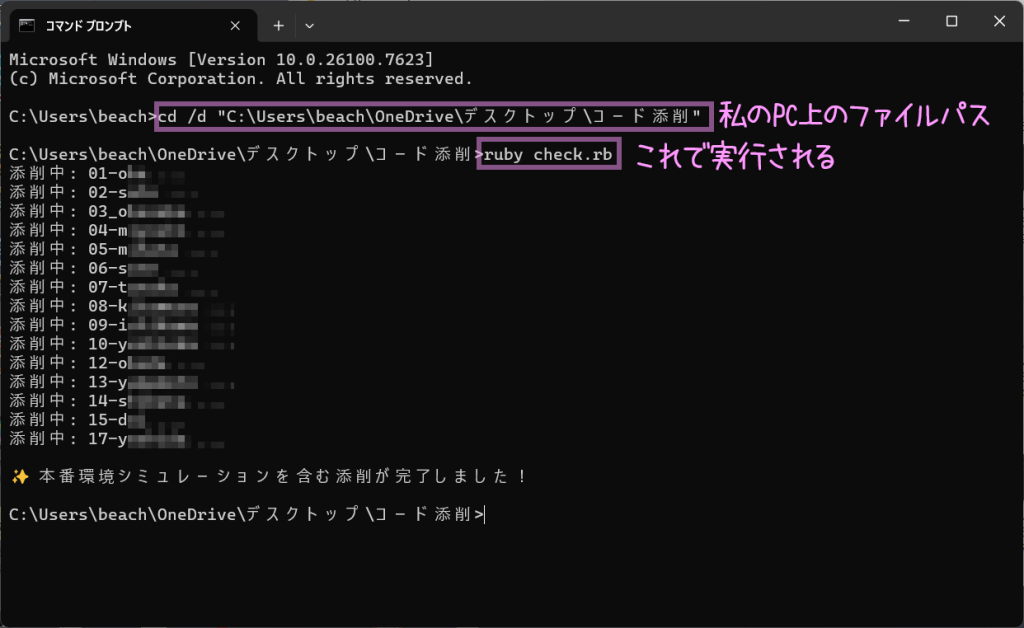
HTMLとCSSをチェックするスクリプトの結果の見方
HTMLとCSS、チェックの結果が表示されたら、実際のファイルを開いて、該当箇所を確認。
CSSは、同じファイル内に重複箇所があれば出してきますが、メディアクエリ内のものも重複で出してきます。なのでPC用とスマホ用のCSSを書いていれば重複に表示されます。
それから、CSSにはあるけど、HTMLにはそのクラス名やID名がない場合も表示されます。
おまけ:Geminiにプログラムの紹介文を考えてもらった
余談:このプログラムができた背景
冬休みの宿題
私はサーバーにアップして、まとめサイトに掲載するだけで疲れたので、各自が自分でアップされた自分のサイトを見て、リンク切れ等に自分で気が付いて、自分で直してよ~、と思っていたのだが・・・
相方のコーディングの先生がひとり、ひとりにフィードバック返してくれて、感動😭
(ほんと、相方は講師に向いてるんよね。一人一人に向き合ってくれてるし、立派)
・・・と、言いつつ、そもそも各自が自分でバリデーションしたらよいことではないか?
↓習っているはずなんだがな🫠(教科書にも書いているし、相方も教えていたはず…)
https://validator.w3.org/ (W3C マークアップ検証サービス)
https://css-validator.org/validator.ja.html (W3C CSS Validation Service)
各生徒のコードに不備がないか、それを時間外にチェックする重労働よ・・・🫠と感じたので、自動で添削するプログラムをつくってみた。とはいっても、Geminiに教えてもらったんだけど。
結論から言うと、無料で動かしたかったので、自分のPCにRubyをインストールしたの。
これはあくまでも相方の姿を見て、相方の手間を省くために考えたものなんだけど、公開することで「自分でやってみよう」と思う人はやってほしいなぁ~。(と、自分のクラスの人が見ていて、自分でもやってみることを期待w)
・・・相方の先生には「こんなの作ったよー」って伝えたんだけど、このプログラムを作った本人であるGeminiに、なんて言ったらいいと思う?と聞いたところ、紹介文を考えてくれたので、掲載しておくよ。
プログラム名:『自走力を育てる!HTML/CSS添削アシスタント』
このプログラムは、講師の目視チェックを大幅に効率化し、生徒が自分では気づきにくい「おしいミス」を自動でリストアップするツールです。
1. 初学者の「ハマりポイント」を逃さず検出
初心者が数時間悩んでしまうような、小さな「書式ミス」を即座に見つけます。
- 「パスの半角スペース」検知
href="index.html #news"のように、ファイル名と#の間にスペースがあると、一部の環境でリンクが機能しません。これを「スペースを詰めましょう」と具体的に指摘します。
- 「ID名に#」検知
id="#top"と書いてしまうミス(正解はid="top")は非常に多いですが、これを見逃さず修正を促します。
- 「大文字・小文字の不一致」検知
- 自分のパソコン(Windows等)では動くのに、提出サーバーでは動かない原因になるファイル名のスペルミスを特定します。
2. コードの「整理・美しさ」へのアドバイス
単に「動く」だけでなく、プロとして必要な「メンテナンス性の高いコード」を教えるきっかけを作ります。
- 「未使用CSS」の自動特定(リファクタリング機能)
- ここがポイント!:「CSSに定義はあるが、HTML側で一度も使われていないクラスやID」をリストアップします。
- 過去の課題のCSSを流用して不要なコードが残っている場合や、HTMLとCSSで名前が食い違っている(スペルミス)場合に非常に有効です。
- 「冗長なパス」の最適化
- 同じフォルダ内のファイルへリンクするのに、わざわざ
../で外に出てから自分自身のフォルダを指定するような、不自然な書き方を検知します。
- 同じフォルダ内のファイルへリンクするのに、わざわざ
3. 添削業務のスピードアップと標準化
- レポート自動生成: 実行すると生徒ごとの「添削レポート.txt」が生成されます。そのままフィードバックとして返却可能です。
- 多階層プロジェクト対応: 複数のフォルダに分かれた複雑な課題も、一括でスキャンして
index.htmlの有無からチェックします。
先生方へ伝える際の「おすすめの言葉」
「このツールを使うと、『スペルミス探し』という単純作業から解放されます。 浮いた時間で、生徒さんのデザイン構成やアクセシビリティについてなど、人間にしかできないより高度なアドバイスに時間を使えるようになりますよ!」